When we launched Skald, we wanted it to not only be self-hostable, but also for one to be able to run it without sending any data to third-parties.
With LLMs getting better and better, privacy-sensitive organizations shouldn't have to choose between being left behind by not accessing frontier models and doing away with their committment to (or legal requirement for) data privacy.
So here's what we did to support this use case and also some benchmarks comparing performance when using proprietary APIs vs self-hosted open-source tech.
RAG components and their OSS alternatives
A basic RAG usually has the following core components:
- A vector database
- A vector embeddings model
- An LLM
And most times it also has these as well:
- A reranker
- Document parsing (for PDFs, PowerPoints, etc)
What that means is that when you're looking to build a fully local RAG setup, you'll need to substitute whatever SaaS providers you're using for a local option for each of those components.
Here's a table with some examples of what we might use in a scenario where we can use third-party Cloud services and one where we can't:
| Component | Proprietary Options | Open-Source Options |
|---|---|---|
| Vector Database | Pinecone, Turbopuffer, Weaviate Cloud, Qdrant Cloud | Qdrant, Weaviate, Postgres with pgvector |
| Vector Embeddings Provider | OpenAI, Cohere, Voyage | Sentence Transformers, BGE, E5 |
| LLM | GPT, Claude, Gemini | Llama, Mistral, GPT-OSS |
| Reranker | Cohere, Voyage | BGE Reranker, Sentence Transformers Cross-Encoder |
| Document Parsing | Reducto, Datalab | Docling |
Do note that running something locally does not mean it needs to be open-source, as one could pay for a license to self-host proprietary software. But at Skald our goal was to use fully open-source tech, which is what I'll be convering here.
The table above is far from covering all available options on both columns, but basically it gives you an indication of what to research into in order to pick a tool that works for you.
As with anything, what works for you will greatly depend on your use case. And you need to be prepared to run a few more services than you're used to if you've just been calling APIs.
For our local stack, we went with the easiest setup for now to get it working (and it does! see writeup on this lower down) but will be running benchmarks on all other options to determine the best possible setup.
This is what we have today:
Vector DB: Postgres + pgvector. We already use Postgres and didn't want to bundle another service into our stack, but this is controversial and we will be running benchmarks to make a better informed decision here. Note that pgvector will serve a lot of use cases well all the way up to hundreds of thousands of documents, though.
Vector embeddings: Users can configure this in Skald and we use Sentence Transformers (all-MiniLM-L6-v2) as our default (solid all-around performer for speed and retrieval, English-only). I also ran Skald with bge-m3 (larger, multi-language) and share the results later in this post.
LLM: We don't even bundle a default with Skald and it's up to the users to run and manage this. I tested our setup with GPT-OSS 20B on EC2 (results shown below).
Reranker: Users can also configure this in Skald, and the default is the Sentence Transformers cross encoder (solid, English-only). I've also used bge-reranker-v2-m3 and mmarco-mMiniLMv2-L12-H384-v1 which offer multi-lingual support.
Document parsing: There isn't much of a question on this one. We're using Docling. It's great. We run it via docling-serve.
Does it perform though?
So the main goal here was first to get something working then ensure it worked well with our platform and could be easily deployed. From here we'll be running extensive benchmarks and working with our clients to provide a solid setup that both performs well but is also not a nightmare to deploy and manage.
From that perspective, this was a great success.
Deploying a production instance of Skald with this whole stack took me 8 minutes, and that comes bundled with the vector database (well, Postgres), a reranking and embedding service, and Docling.
The only thing I needed to run separately was the LLM, which I did via llama.cpp.
Having gotten this sorted, I imported all the content from the PostHog website [1] and set up a tiny dataset [2] of questions and expected answers inside of Skald, then used our Experiments feature to run the RAG over this dataset.
I explicitly kept the topK values really high (100 for the vector search and 50 for post-reranking), as I was mostly testing for accuracy and wanted to see the performance when questions required e.g. aggregating context over 15+ documents.
Full config
Here are the params configured in the Skald UI for the the experiment.
| Config option | Selection |
|---|---|
| Extra system prompt | Be really concise in your answers |
| Query rewriting | Off |
| Vector search topK | 100 |
| Vector search distance threshold | 0.8 |
| Reranking | On |
| Reranking topK | 50 |
| References | Off |
So without any more delay, here are the results of my not-very-scientific at all benchmark using the experimentation platform inside of Skald.
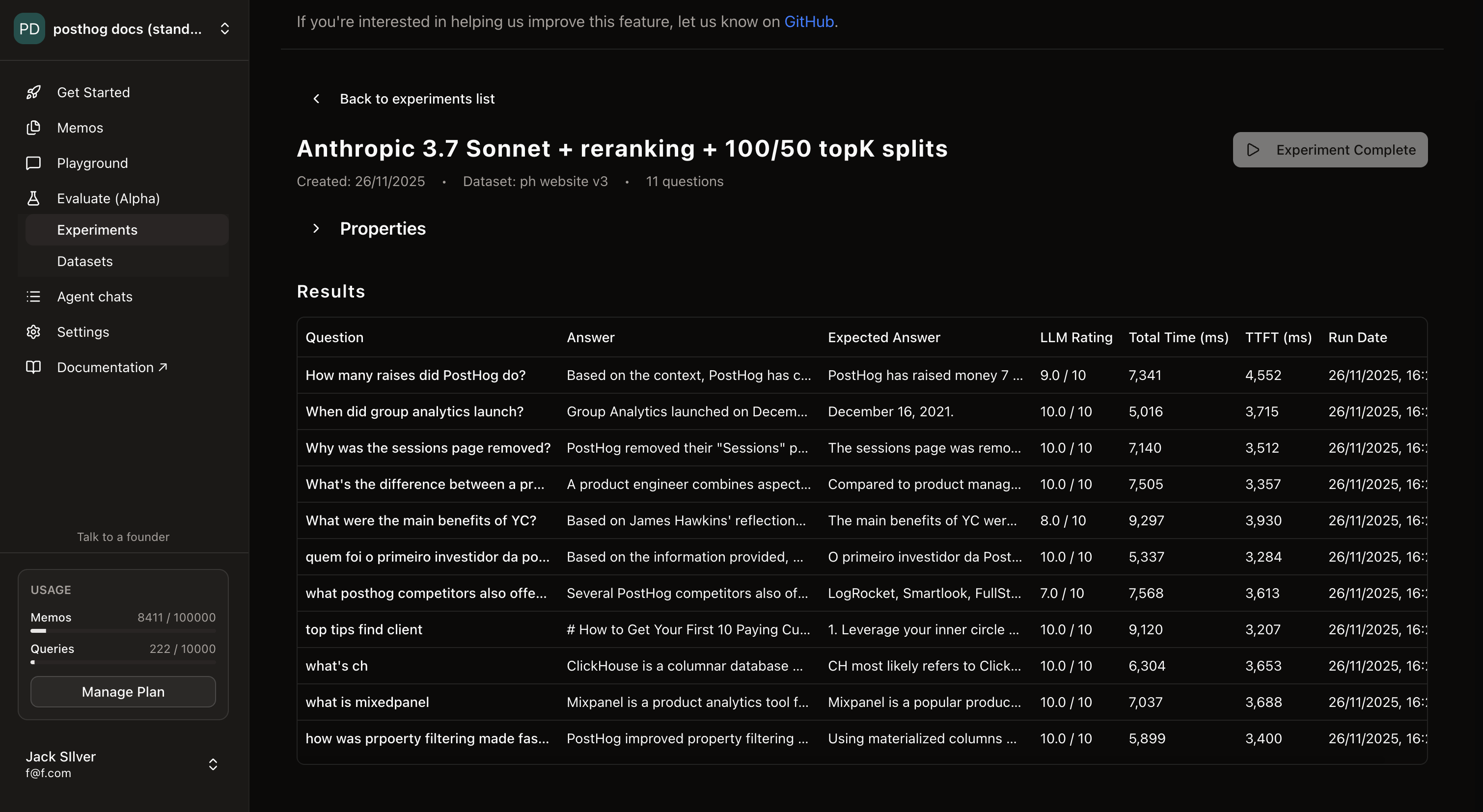
Voyage + Claude
This is our default Cloud setup. We use voyage-3-large and rerank-2.5 from Voyage AI as our embedding and reranking models respectively, and we default to Claude Sonnet 3.7 for responses (users can configure the model though).
It passed with flying colors.
Our LLM-as-a-Judge gave an average score of 9.45 to the responses, and I basically agree with the assessment. All answers were correct, with one missing a few extra bits of context.
Voyage + GPT-OSS 20B
With the control experiment done, I then moved on to a setup where I kept Voyage as the embeddings provider and reranker, and then used GPT-OSS 20B running on a llama.cpp server on a g5.2xlarge EC2 instance as the LLM.
The goal here was to see how well the open-source LLM model itself stacked up against a frontier model accessed via API.
And it did great!
We don't yet support LLM-as-a-Judge on fully local deployments, so the only score we have here is mine. I scored the answers an average of 9.18 and they were all correct, with two of them just missing a few bits of information or highlighting less relevant information from the context.
Fully local + GPT-OSS 20B
Lastly, it was time for the moment of truth: running a fully local setup.
For this I ran two tests:
1. Default sentence transformers embedding and reranking models
The most popular open-source models are all-MiniLM-L6-v2 for embeddings and ms-marco-MiniLM-L6-v2 as the reranker, so I used those for my first benchmark.
Here the average score was 7.10. Not bad, but definitely not great. However, when we dig into the results, we can get a better understanding of how this setup fails.
Basically, it got all point queries right, which are questions where the answer is somewhere in the mess of documents, but can be found from one specific place.
Where it failed was:
- Non-english query: The embeddings model and the reranker are English-based, so my question in Portuguese obviously got no answer
- An ambiguous question with very little context ("what's ch")
- Aggregating information from multiple documents/chunks e.g. it only found 5 out of PostHog's 7 funding rounds, and only a subset of the PostHog competitors that offer session replay (as mentioned in the source data)
In my view, this is good news. That means that the default options will go a long way and should give you very good performance if your use case is only doing point queries in English. The other great thing is that these models are also fast.
Now, if you need to handle ambiguity better, or handle questions in other languages, then this setup is simply not for you.
2. Multi-lingual models
The next test I did used bge-m3 as the embeddings model and mmarco-mMiniLMv2-L12-H384-v1 as the reranker. The embeddings model is supposedly much better than the one used in the previous test and is also multi-lingual. The reranker on the other hand uses the same cross-encoder from the previous test as the base model but also adds multi-lingual support. The more standard option here would have been the much more popular bge-reranker-v2-m3 model, but I found it to be much slower. I intend to tweak my setup and test it again, however.
Anyway, onto the results! I scored it 8.63 on average, which is very good. There were no complete failures, and it handled the question in Portuguese well.
The mistakes it made were:
- This new setup also did not do the best job at aggregating information, missing 2 of PostHog's funding rounds, and a couple of its session replay competitors
- It also answered a question correctly, but added incorrect additional context after it
So overall it performed quite well. Again what we what saw was the main problem is when the context needed for the response is scattered across multiple documents. There are various techniques to help with this and we'll be trialing some soon! They haven't been needed on the Cloud version because better models save you from having to add complexity for minimal performance gains, but as we're focused on building a really solid setup for local deploys, we'll be looking into this more and more.
Now what?
I hope this writeup has provided you with at least some insight and context into building a local RAG, and also the fact that it does work, it can serve a lot of use cases, and that the tendency is for this setup to get better and better as a) models improve b) we get more open-source models across the board, with both being things that we seem to be trending towards.
As for us at Skald, we intend to polish this setup further in order to serve even more use cases really well, as well as intend to soon be publishing more legitimate benchmarks for models in the open-source space, from LLMs to rerankers.
If you're a company that needs to run AI tooling in air-gapped infrastructure, let's chat -- feel free to email me at yakko [at] useskald [dot] com.
Lastly, if you want to get involved, feel free to chat to us over on our GitHub repo (MIT-licensed) or catch us on Slack.
Footnotes
[1] I used the PostHog website here because the website content is MIT-licensed (yes, wild) and readily-available as markdown on GitHub and having worked there I know a lot of answers off the top of my head making it a great dataset of ~2000 documents that I know well.
[2] The questions and answers dataset I used for the experiments was the following:
Dataset
| Question | Expected answer | Comments |
|---|---|---|
| How many raises did PostHog do? | PostHog has raised money 7 times: it raised $150k from YCombinator, then did a seed round ($3.025M), a series A ($12M), a series B ($15M), a series C ($10M), a series D ($70M), and a series E ($75M). | Requires aggregating context from at least 7 documents |
| When did group analytics launch? | December 16, 2021. | Point query, multiple mentions to "group analytics" in the source docs |
| Why was the sessions page removed? | The sessions page was removed because it was confusing and limited in functionality. It was replaced by the 'Recordings' tab. | Point query, multiple mentions to "sessions" in the source docs |
| What's the difference between a product engineer and other roles? | Compared to product managers, product engineers focus more on building rather than deep research and planning. When it comes to software engineers, both product and software engineers write code, but software engineers focus on building great software, whereas product engineers focus on building great products. | Requires aggregating context from multiple docs + there are a ton of mentions of "product engineer" in the source docs |
| What were the main benefits of YC? | The main benefits of YC were: Network Access, Investor Reviews, Office Hours, Funding Opportunities, Hiring Resources, Angel Investing Opportunities, Accelerated Growth and Experience, Shift in Self-Perception, Customer Acquisition, Product Market Fit, Ambitious Goal Setting, Access to Thought Leaders, Community Support | Point query |
| quem foi o primeiro investidor da posthogg? | O primeiro investidor da PostHog foi o YCombinator. | Question in Portuguese, with PostHog misspelled |
| what posthog competitors also offer session replays | LogRocket, Smartlook, FullStory, Microsoft Clarity, Contentsquare, Mouseflow, Heap, Pendo, Hotjar, Glassbox, and Amplitude. | Requires aggregating content from at least 11 docs (more because I actually missed some in my expected answer) |
| top tips find client | 1. Leverage your inner circle 2. Join relevant communities 3. Be laser-focused 4. Set achievable goals 5. Frame conversations properly | Point query, worded weirdly |
| what's ch | CH most likely refers to ClickHouse, a column-oriented OLAP database. | Really ambiguous. I meant ClickHouse with my question. |
| what is mixedpanel | Mixpanel is a popular product analytics tool that was founded in 2009 | Mixpanel misspelled as Mixedpanel |
| how was prpoerty filtering made faster? | Using materialized columns allowed ClickHouse to skip JSON parsing during queries and made queries with property filtering 25x faster. | Point query with a typo |